
Python基礎講座の第8回目です。
マージソート(Merge Sort)について解説します。
基本情報技術者試験にも出題される基本的なアルゴリズムなので、しっかり理解していきましょう。
マージソートとは
マージソートはソートアルゴリズムの1つです。
(ソートアルゴリズムについては第5回の「ソートアルゴリズムとは」で説明しています。)
概要図
概要を図にするとこのようなソートになります。
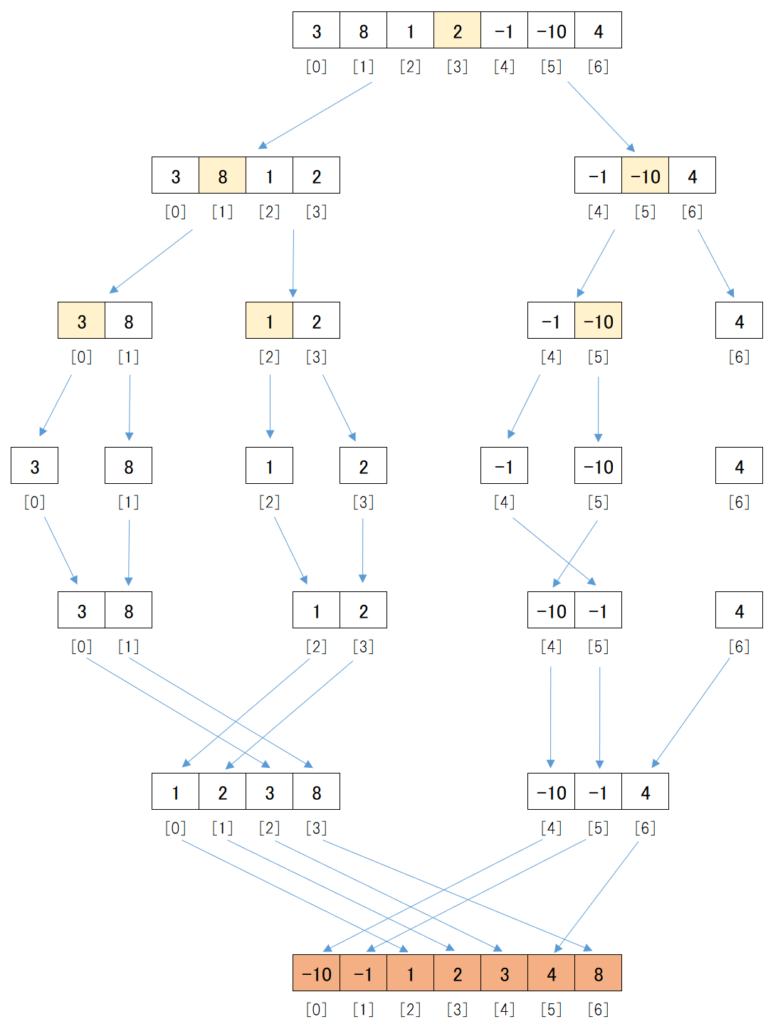
データの下に記載している[0]や[1]はデータの位置を示します。
プログラムはデータの先頭を1番ではなく0番と認識するので、それにあわせて0番から記載しています。
概要
それではマージソートがどのようなソートか説明していきます。
マージソートでは、データの分割と結合を繰り返してデータを並べ替えます。
・昇順(小さい順)に並べる場合
- データが1つになるまで分割を繰り返す
- 分割したデータを昇順になるように結合する
・降順(大きい順)に並べる場合
- データが1つになるまで分割を繰り返す
- 分割したデータを降順になるように結合する
昇順と降順どちらで並べる場合も分割の処理は同じです。
分割したデータを結合していく時に、昇順なら昇順に並べ、降順なら降順に並べます。
では、実際に[3, 8, 1, 2, -1, -10, 4]を昇順にソートしてみましょう。
まずデータを中央で2つに分けます。
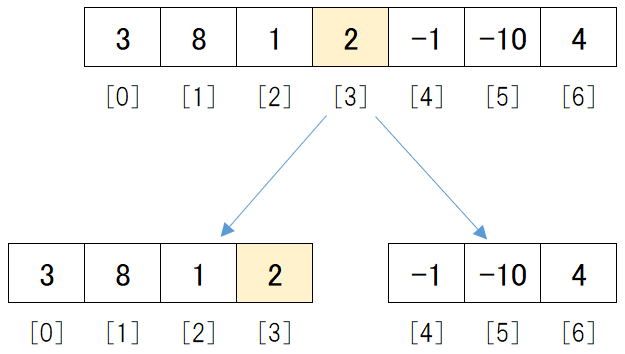
中央の決め方は「(先頭のデータの位置 + 末尾のデータの位置) / 2」 です。
小数点以下は切り捨てます。
つまり、今回の場合は(0 + 6) / 2 = 3 となります。
そこで、[3]の位置で2つに分けると、図のように前半のデータは[3, 8, 1, 2]、後半のデータは[-1, -10, 4]となります。
まずマージソートがどういうものか理解しやすいように、先に分割する流れを説明した後に結合していく流れを見ていきます。
アルゴリズムの正しい順序はコード解説のところで詳しく説明します。
ここでは概要を理解してください。
前半のデータ[3, 8, 1, 2]は、まだデータが2つ以上あります。
1つになるまで分割するので、もう一度データを中央で2つに分けます。
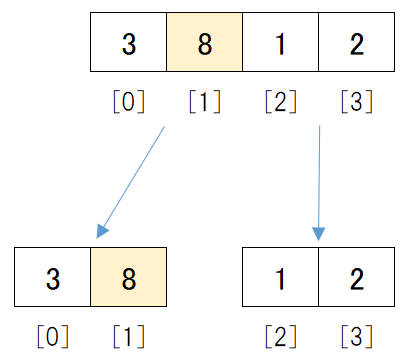
中央のデータの位置は、(0 + 3) / 2 = 1.5となります。
小数点以下は切り捨てるため1となります。
そこで、[1]の位置で2つに分けると、図のように前半のデータは[3, 8]、後半のデータは[1, 2]となります。
前半のデータ[3, 8]は、 まだデータが2つ以上あります 。
1つになるまで分割するので、もう一度データを中央で2つに分けます。
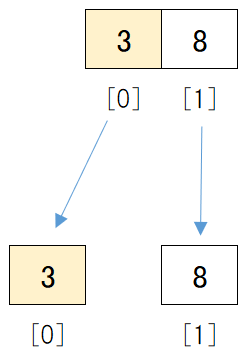
中央のデータの位置は、(0 + 1) / 2 = 0.5となります。
小数点以下は切り捨てるため0となります。
そこで、[0]の位置で2つに分けると、前半のデータは[3]、後半のデータは[8]となります。
ようやくデータが1つになるまで分割することができました。
同じように後半のデータ[1, 2]も1つになるまで分割しましょう。
データを中央で2つに分けます。
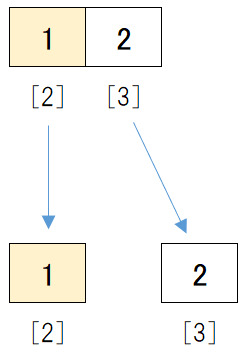
中央のデータの位置は、(2 + 3) / 2 = 2.5となります。
小数点以下は切り捨てるため2となります。
そこで、[2]の位置で2つに分けると、前半のデータは[1]、後半のデータは[2]となります。
こちらもデータが1つになるまで分割することができました。
ここから分割したデータを元に戻していきます。元に戻す時に昇順になるようにソートします。
まず先に分割した[3]と[8]を昇順に並ぶように結合します。
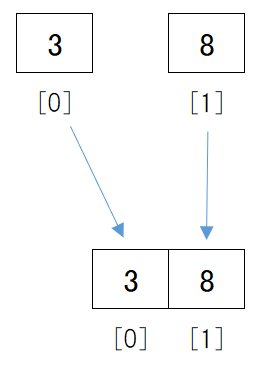
これで[3, 8]というデータができました。
次に[1]と[2]も昇順に並ぶように結合します。
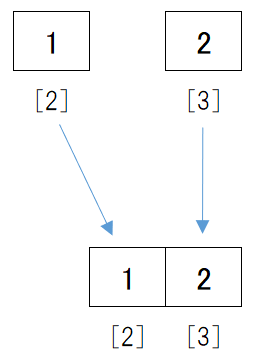
これで[1, 2]というデータができました。
次は[3, 8]と[1, 2]を昇順に並ぶよう結合します。
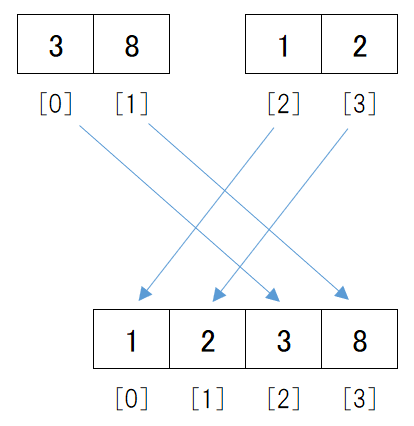
これで[1, 2, 3, 8]というデータができました。
後半の[-1, -10, 4]も同様に、データが1つになるまで分割できたところでデータを昇順になるよう結合していくことでソートします。
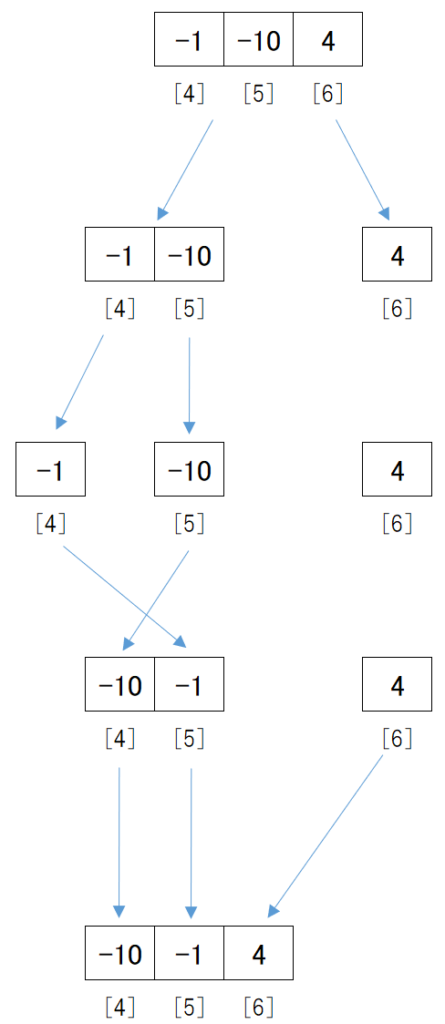
[-10, -1, 4]というデータができます。
最後に[1, 2, 3, 8]と[-10, -1, 4]を昇順になるよう結合します。
これでデータは[-10, -1, 1, 2, 3, 4, 8]となり、昇順にソートできました。
概要が理解できたところで、次はコードを見ながら詳細を理解しましょう。
コード
コードにするとこのようになります。
def merge(data, start, mid, end):
data_temp = []
i = start
j = mid + 1
while i <= mid and j <= end:
if data[i] < data[j]:
data_temp.append(data[i])
i = i + 1
else:
data_temp.append(data[j])
j = j + 1
while i <= mid:
data_temp.append(data[i])
i = i + 1
while j <= end:
data_temp.append(data[j])
j = j + 1
k = start
for val in data_temp:
data[k] = val
k = k + 1
def merge_sort(data, start, end):
if start >= end:
return
mid = (start + end) // 2
merge_sort(data, start, mid)
merge_sort(data, mid + 1, end)
merge(data, start, mid, end)
data = [3, 8, 1, 2, -1, -10, 4]
end = len(data) - 1
merge_sort(data, 0, end)
print(data)コードの解説が少し長いので、このコードをエディタなどにコピーして、解説を読みながらコードが見れるようにしておくと読みやすいです。
コード解説
コードをまとまりごとに整理していきましょう。
2つのメソッドを定義しています。
- merge
- merge_sort
説明の都合上、まずmerge_sortから解説します。
merge_sort
このメソッドの中をよく見ると、31行目と32行目でも自分自身であるmerge_sortを実行しています。
このような自分自身を繰り返し実行する処理を再起処理と呼び、そのメソッドを再起関数と呼びます。
この再起関数は少し難しいので、まず概要を説明し、次に処理を順番に追って説明していきます。
概要
このメソッドでは、データを2分割します。
def merge_sort(data, start, end):と引数が3つあり、それぞれの意味は次のようになります。
- data :マージソートするデータ
- start :データの先頭
- end :データの末尾
先述のように、このmerge_sortは再起関数です。
merge_sortがmerge_sortを呼び、呼び出されたmerge_sortがさらにmerge_sortを呼ぶので、どこかで次の呼び出しを止めないと永遠に自分自身を呼び続けてしまいます。
その次の呼び出しを止める条件が27行目のif start >= endです。
この条件が何を意味しているかについては後で見ていきましょう。
30行目で中央となるデータの位置を求めています。
中央となるデータの位置の求め方は「(先頭データの位置 + 末尾データの位置) / 2」でした。
また、小数点以下は切り捨てるのでしたね。
Pythonではx // 2と書くことで、xを2で割った時の整数部を求めることができます。
そのため(start + end) // 2として、中央となるデータの位置を求めています。
31行目のmerge_sortでは引数が(data, start, mid)、32行目のmerge_sortでは引数が(data, mid + 1, end)となっており、第2引数である先頭データの位置と、第3引数である末尾データの位置が違います。
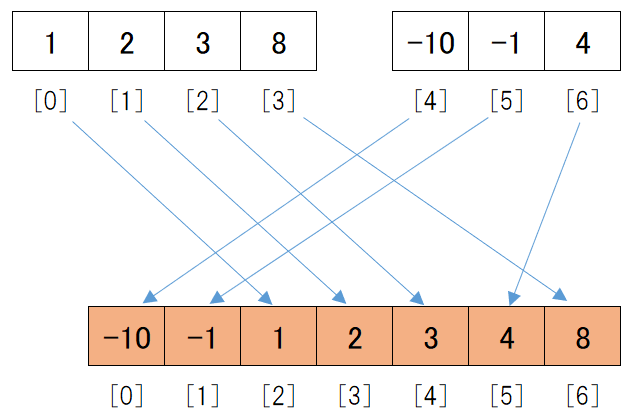
これは以下のようにデータを2分割するためです。
31行目のmerge_sortでは2分割したデータの前半部分となり、32行目のmerge_sortでは2分割したデータの後半部分を意味します。
merge_sortの分割について分かったところで、27行目のif文に戻りましょう。
startはデータの先頭で、endはデータの末尾です。
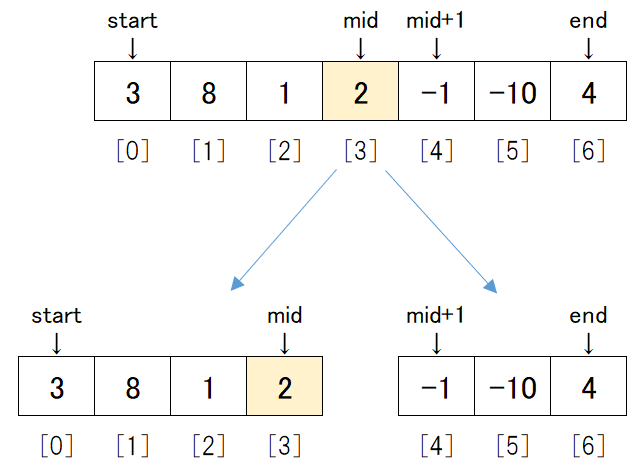
そのうえで、if start >= endとなるのは以下のようにstartとendが同じデータを指した状態です。
以下のような状態も27行目の条件を満たしますが、2分割しながらstartとendを狭めていくので起こりえません。
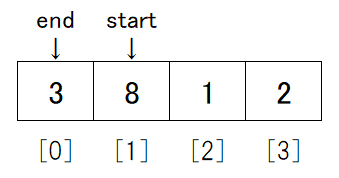
つまり、27行目のif文の条件を満たすのは、データが1つになるまで分割できた状態です。
データが1つになるまで分割されると、28行目のreturnに入ります。
returnで処理が終了し、それ以降にある31行目と32行目のmerge_sortが呼ばれなくなるので、それ以上データが分割されることなく、再起処理が終了できるようになります。
この再起処理の注意点としては、28行目でreturnできなければ、merge_sortがmerge_sortを繰り返し呼び出すので、merge_sortの無限ループになってしまい、処理が永遠に終わらなくなってしまいます。
ここまでをまとめると、merge_sortはデータを前半部分と後半部分に分けて2分割し、merge_sort自身がmerge_sortを呼び出すので、前半部分と後半部分のデータをさらに2分割します。
2分割にする処理は、データが1つになるまで繰り返されます。
再起処理は、処理の順番が複雑になるので、コードを見ながら処理を追っていきましょう。
処理の順番
プログラムのデバッグをしたことがある人は処理の順番をイメージしやすいのですが、merge_sortが呼ばれると31行目でもう一度merge_sortを呼びます。

呼ばれたmerge_sortがまた31行目でmerge_sortを呼びます。
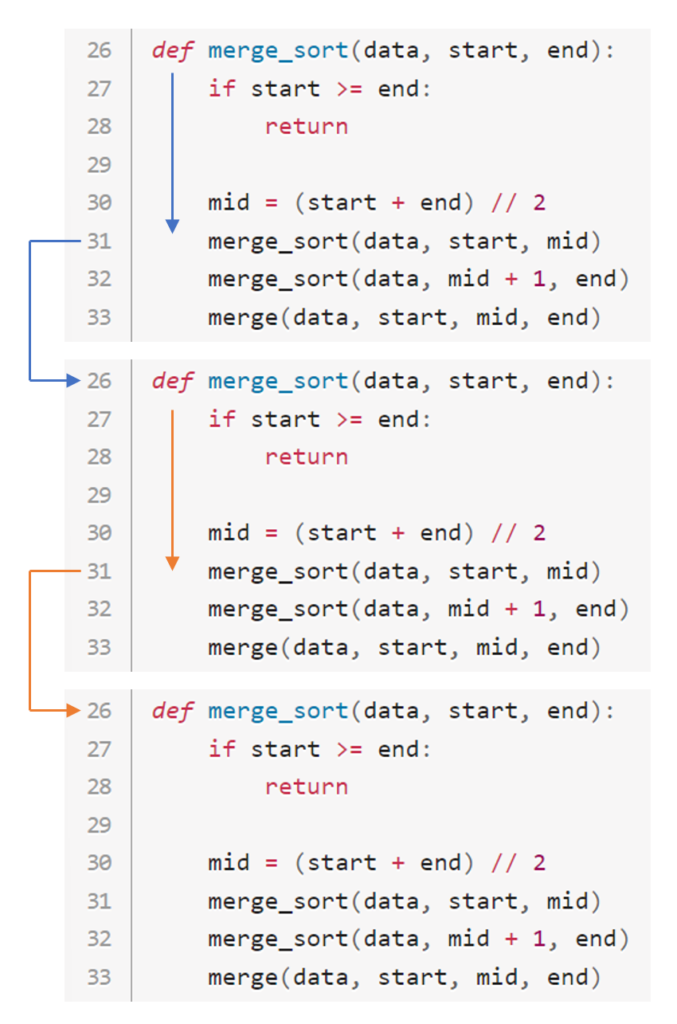
merge_sortの処理が進み、また31行目でmerge_sortが呼ばれます。
このように28行目でreturnしなければ、merge_sortは31行目のmerge_sortを呼び出し続け、32行目以降のコードは永遠に実行されません。
では[3, 8, 1, 2, -1, -10, 4]をソートする場合、どのような時に28行目でreturnするのか図で見てみましょう。
図の左側がコードの呼び出し順で、右側はその時のデータです。

このような流れで4度目のmerge_sortが実行され、赤色矢印で1度目のreturnに入ります。
この図を見ながらコードを最初から追っていきしょう。
プログラムが実行されると、まず37行目のmerge_sortが呼ばれます。
merge_sortが実行されると、図の青色矢印の流れで処理は進みます。
startの値は0でendの値は6なので27行目のif文に入らず、そのまま処理が進みます。
30行目でmidに中央のデータの位置が指定されます。
この時のmidは(0 + 6) / 2 = 3となります。
31行目のmerge_sortに到達し、2度目のmerge_sortが実行されます。
2度目のmerge_sortに渡される引数は以下のようになります。
- data = [3, 8, 1, 2, -1, -10, 4]
- start = 0
- end = mid = 3
2度目のmerge_sortが実行されると、図のオレンジ矢印の流れで処理は進みます。
startの値は0でendの値は3なので27行目のif文に入らず、そのまま処理が進みます。
30行目でmidに中央のデータの位置が指定されます。
この時のmidは(0 + 3) / 2 = 1.5となり、整数部の1となります。
31行目のmerge_sortに到達し、3度目のmerge_sortが実行されます。
3度目のmerge_sortに渡される引数は以下のようになります。
- data = [3, 8, 1, 2, -1, -10, 4]
- start = 0
- end = mid = 1
3度目のmerge_sortが実行されると、図の緑色矢印の流れで処理は進みます。
startの値は0でendの値は1なので27行目のif文に入らず、そのまま処理が進みます。
30行目でmidに中央のデータの位置が指定されます。
この時のmidは(0 + 1) / 2 = 0.5となり、整数部の0となります。
31行目のmerge_sortに到達し、4度目のmerge_sortが実行されます。
4度目のmerge_sortに渡される引数は以下のようになります。
- data = [3, 8, 1, 2, -1, -10, 4]
- start = 0
- end = mid = 0
4度目のmerge_sortが実行されると、startの値は0でendの値は0なので、ついに27行目のif文に入ります。
図の赤色矢印の流れで処理は進み、28行目でreturnして4度目のmerge_sortを終了します。
4度目のmerge_sortが終わったので、3度目のmerge_sortに処理が戻ります。
これで3度目のmerge_sortの31行目の処理が終わりました。
次は32行目に移ります。(以下の図の緑色矢印)

32行目のmerge_sortは以下の引数で実行されます。
- data = [3, 8, 1, 2, -1, -10, 4]
- start = mid +1 = 1
- end = 1
32行目のmerge_sortが実行されると、startの値は1でendの値は1なので27行目のif文に入ります。
図の赤色矢印の流れで処理は進み、28行目でreturnして赤色merge_sortを終了します。
赤色merge_sortが終わったので、緑色merge_sortに処理が戻ります。
これで緑色merge_sortの32行目の処理が終わりました。
次は33行目に移ります。

33行目はmergeです。
今はmerge_sortの再起処理の流れを理解してほしいため、mergeの中身の説明は後で行います。
ここでは、mergeでstartとendの範囲のデータを昇順に並べると思っておいてください。
33行目のmergeを実行します。
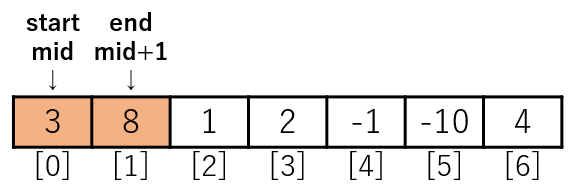
startとendの範囲のデータが昇順に並びました。
これで緑矢印の処理は最後まで終わったので、オレンジ矢印の処理に戻ります。
オレンジ矢印では31行目が終わったので、次は32行目に移ります。
32行目のmerge_sortが実行されると、図の紫色矢印の流れで処理が進みます。
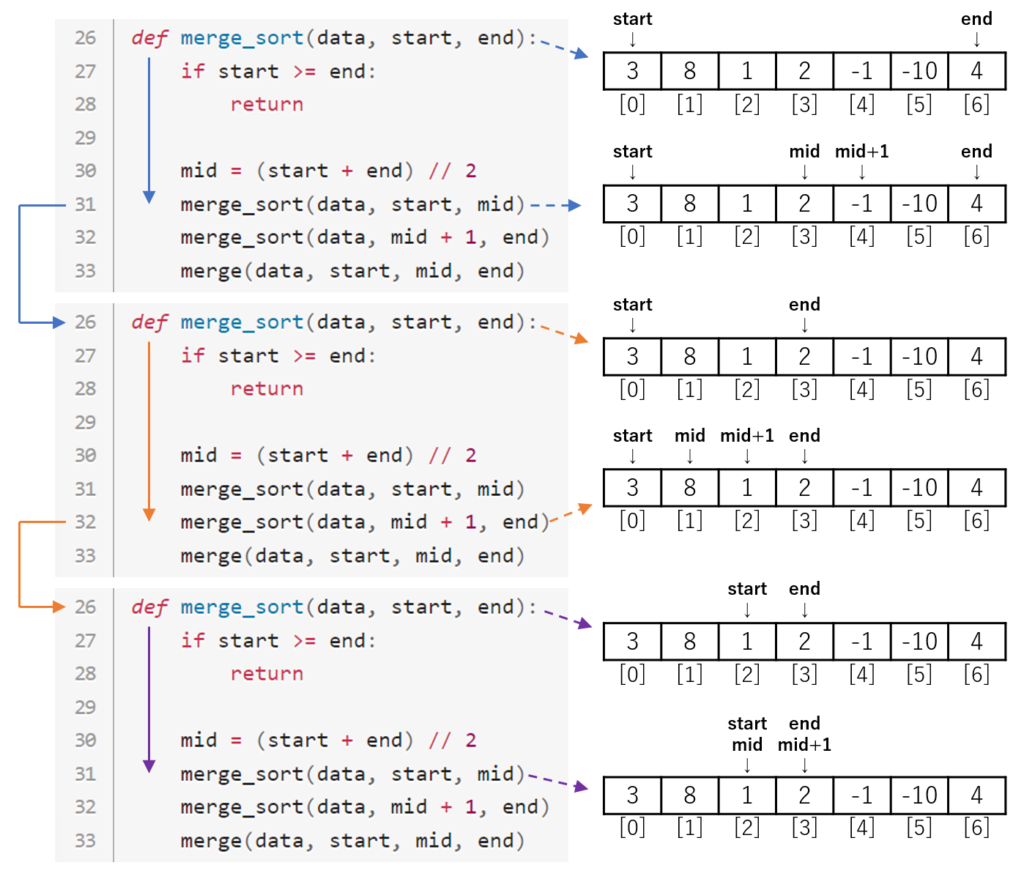
この時オレンジ矢印の処理から紫色に渡される引数は以下です。
- data = [3, 8, 1, 2, -1, -10, 4]
- start = mid = 2
- end = 3
startの値は2でendの値は3なので27行目のif文に入らず、そのまま処理が進みます。
30行目でmidに中央のデータの位置が指定されます。
この時のmidは(2 + 3) / 2 = 2.5となり、整数部の2となります。
31行目のmerge_sortに到達し、以下の赤色矢印のmerge_sortが実行されます。

赤色merge_sortに渡される引数は以下のようになります。
- data = [3, 8, 1, 2, -1, -10, 4]
- start = 2
- end = mid = 2
startの値は2でendの値は2なので、27行目のif文に入ります。
28行目でreturnし、赤色merge_sortの処理を終了します。
赤色merge_sortの処理が終わったので、紫色merge_sortに処理が戻ります。
これで紫色merge_sortの31行目の処理が終わりました。
次は32行目に移ります。

32行目のmerge_sortは以下の引数で実行されます。
- data = [3, 8, 1, 2, -1, -10, 4]
- start = mid +1 = 3
- end = 3
32行目のmerge_sortが実行されると、startの値は3でendの値は3なので、27行目のif文に入ります。
図の赤色矢印の流れで処理は進み、28行目でreturnして赤色merge_sortは終了します。
赤色merge_sortが終わったので、紫色merge_sortに処理が戻ります。
これで紫色merge_sortの32行目の処理が終わりました。
次は33行目に移ります。
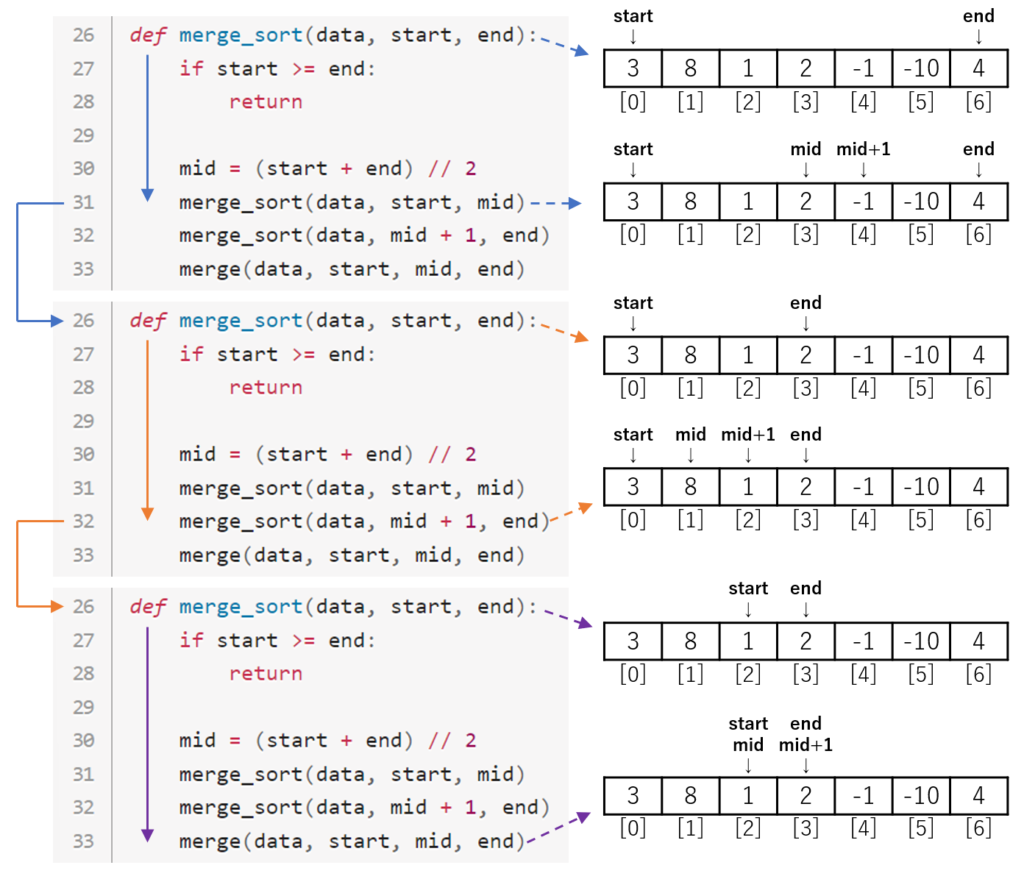
33行目はmergeです。
先ほどと同様、mergeの中身の説明は後で行います。
mergeでstartとendの範囲のデータが昇順に並びます。
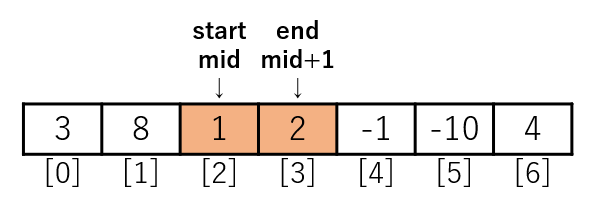
startとendの範囲のデータが昇順に並びました。
これで紫色矢印の処理はメソッドの最後まで終わりましたので、オレンジ矢印の処理に戻ります。
オレンジ矢印では、32行目が終わったので次は33行目に移ります。

また33行目のmergeです。
mergeでstartとendの範囲のデータを昇順に並べます。
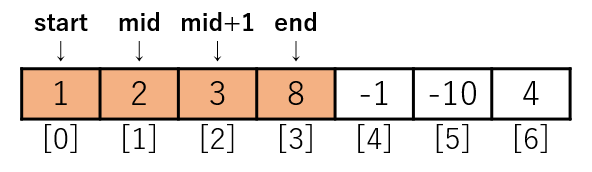
これで[3, 8, 1, 2, -1, -10, 4]の前半分[3, 8, 1, 2]を[1, 2, 3, 8]と昇順に並べることができました。
後ろ半分の[-1, -10, 4]も同様の処理を繰り返すことで、[-10, -1, 4]と昇順に並びます。
最後に、前半分の[1, 2, 3, 8]と後ろ半分の[-10, -1, 4]をmergeで昇順に並べることで、[-10, -1, 1, 2, 3, 4, 8]とソートされます。
merge
先ほど飛ばしたmergeについて説明していきます。
merge_sortの説明のところで見たように、mergeは何度も実行され、実行されるたびにmerge_sortで分割されたデータを結合してデータを昇順に並べていきます。
結果としては以下のようにソートされます。
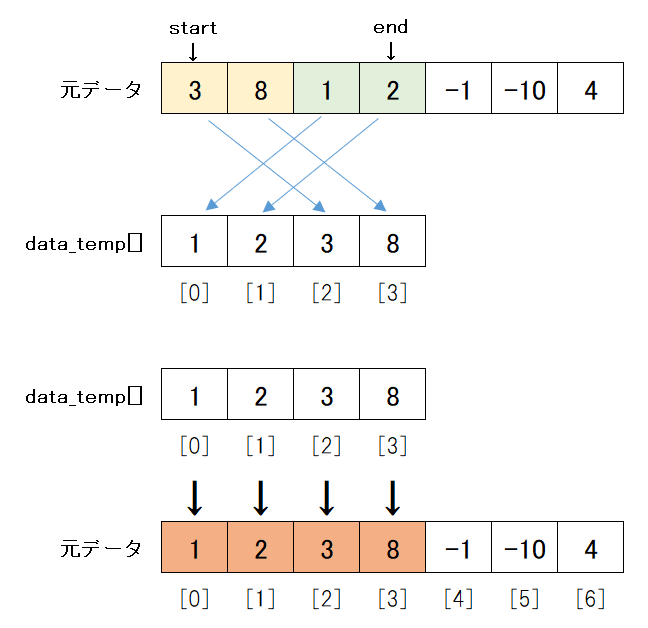
data_tempという一時領域を作成し、そこへstartからendまでのデータを昇順に入れていきます。
その後、data_tempで昇順に並んだデータを使って、元データを上書きます。
では実際どのように処理が進んでいくのかmergeのコードを追ってみましょう。
先ほど見た[3, 8, 1, 2]を[1, 2, 3, 8]に並べた時のコードを使って説明していきます。
まず、merge実行前のコードとデータは以下のようになっていました。
この時、33行目のmergeは、以下の引数で実行されます。
- data = [3, 8, 1, 2, -1, -10, 4]
- start = 0
- mid = 1
- end = 3
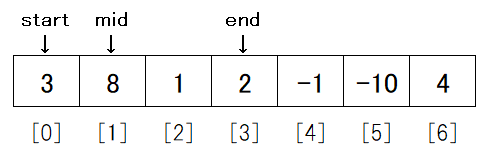
実行されたmergeは、まず2~4行目でdata_temp, i, jを作ります。
data_tempの役割は、昇順に並べたデータを入れておくための一時的な箱になります。
まずstartからendまでのデータをdata_tempに昇順で並べます。
次に、data_tempに保存された昇順に並んだデータで元データを上書きすることで、引数で指定されたstartからendまでの範囲でデータがソートされます。
では i と j はどういう役割でしょうか。
i にstartを、jにmid + 1を入れてみます。
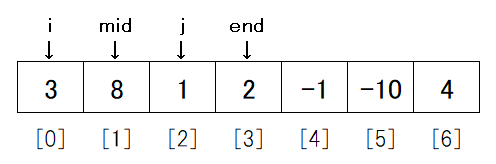
merge_sortの説明のところで見ましたが、この段階で[3], [8], [1], [2]は既に[3, 8]と[1, 2]に並べられています。
前半の[3, 8]と後半の[1, 2]に色をつけてみましょう。
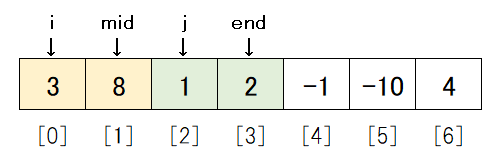
つまり、i は前半データの先頭を表し、 j は後半データの先頭を表しています。
5行目はwhileでループしています。
このループでは、昇順に並ぶようにdata_tempにデータを入れていきます。
ループを繰り返す条件は後で見るとして、まず6~11行目が何を意味するか見ていきましょう。
まず6行目でdata[i] と data[j]の大小を比較しています。
i は前半データの先頭を表し、 j は後半データの先頭を意味しました。
そこで、もしdata[j] より data[i]のほうが小さければ、7行目でdata_tempにはdata[i]を入れます。
反対にdata[i] より data[j]のほうが小さければ、10行目でdata_tempにはdata[j]を入れます。
このように小さいほうからdata_tempにデータを繰り返し入れていくことで、data_tempには昇順に並んだデータが作られていきます。
今回の場合はdata[i]は3でdata[j]は1なので、data[i] より data[j]のほうが小さいです。
そのため6行目のifではなく9行目のelseに入り、data_tempは[1]となります。
data_tempにデータを詰めたら、詰めたほうのデータを1つ先に進めるため、8行目もしくは15行目でi もしくは j を1大きくします。
今回の場合は、11行目が実行されるので、データは以下のようになります。
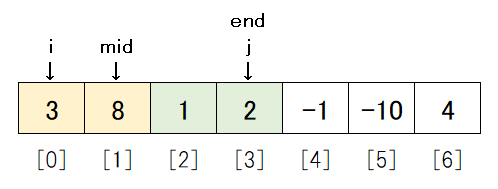
これで1度目のループが終了です。
5行目のループを繰り返す条件を見ていきましょう。
繰り返しの条件は i <= mid and j <= endとなっています。
つまり、前半部分か後半部分どちらかのデータが保存されきるまで処理を繰り返します。
次のループでは、data[i]は3でdata[j]は2なので、またdata[i] より data[j]のほうが小さいです。
そのため6行目のifではなく9行目のelseに入り、data_tempは[1, 2]となります。
その後 j が1大きくなりデータは以下のようになります。
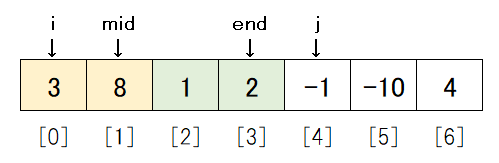
これは j > end となっており、先ほど確認した繰り返しの条件 i <= mid and j <= end を満たしていません。
これで5行目のループは終わります。
次は13行目ですが、ここもwhileループです。
よく見ると、この13行目のwhileループの条件は、5行目のwhileループの条件の前半部分と同じです。
少し先ですが17行目のwhileループの条件は、5行目のwhileループの条件の後半部分と同じになっています。
5行目のループが終了するということは、whileループの条件の前半部分「i <= mid」もしくは後半部分「j <= end」のどちらかが既に満たされない状態となっています。
つまり、5行目のループが終了した時点で、13行目のwhileループもしくは17行目のwhileループのどちらかは実行されません。
13行目のwhileループもしくは17行目のwhileループのどちらかしか実行されないことが分かったところで、このループで何をしているか見ていきましょう。
このループでは、まだ保存されていないデータの前半部分もしくは後半部分をdata_tempに追加します。
具体的に見ていきましょう。
今回の場合は5行目のwhileループで j > endとなりました。
そのため、17行目のwhileループは実行されず、13行目のwhileループのみが実行されます。
13行目のwhileループが1度実行されると、data_tempは[1, 2, 3]となります。
データの状態は i が1大きくなるので、以下のようになります。
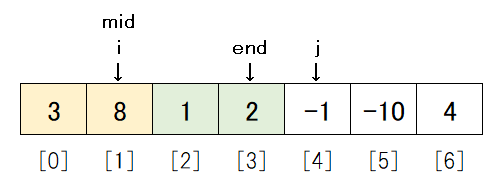
まだ i <= mid のため、もう一度ループします。
2度目が実行されると、data_tempは[1, 2, 3, 8]となります。
データの状態はiが1大きくなるので、以下のようになります。
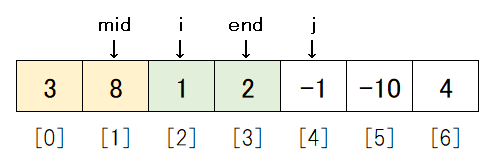
i > midとなったため、これで13行目のループは終了です。
先ほど説明したように17行目のループは実行されないため、次は21行目です。
21~24行目ではdata_tempに保存された[1, 2, 3, 8]で、元のデータ[3, 8, 1, 2, -1, -10, 4]を上書きします。
21行目では k に start を入れています。
kは上書きする元データの位置を表しており、まず先頭データの位置であるstartを入れます。
22行目でdata_tempの先頭から1つデータを取り出し、取り出したデータにvalという名前をつけています。
23行目で取り出したvalで元データを置き換えます。
24行目でkを1大きくし、上書きする元データの位置を1つ先に進めます。
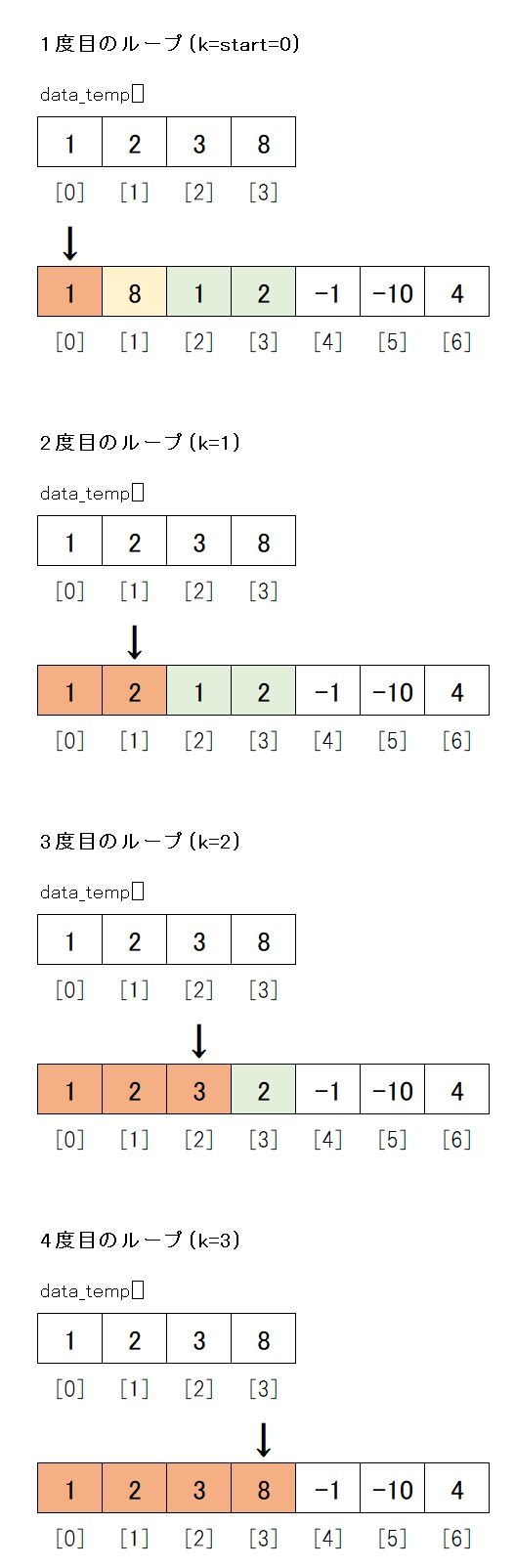
このように、data_tempに保存されたデータの数だけループし、元データを上書くことで、[1, 2, 3, 8, -1, -10, 4]というデータができました。
このようにしてデータが結合され、最終的には[-10, -1, 1, 2, 3, 4, 8]というデータが完成します。
実行結果
コードを実行して昇順にソートされることを確認しましょう。

ちゃんと昇順にソートされていますね。
最後に & 関連書籍
以上、第8回目はマージソートでした。
基本情報技術者試験にも出題される基本のアルゴリズムですので、しっかり理解しておきましょう。
以下の記事で他のソートアルゴリズムについても解説しています。
興味があれば読んでみてください。

以下では探索アルゴリズムを解説しています。
こちらも基本のアルゴリズムとなりますので、しっかり理解しておきましょう。

分かりにくいところや「もっとこうしてほしい」などのご意見がありましたら、ツイッターから連絡いただけると幸いです。
質問に関してもお気軽にお問い合わせください。
以下は関連書籍です。


コメント